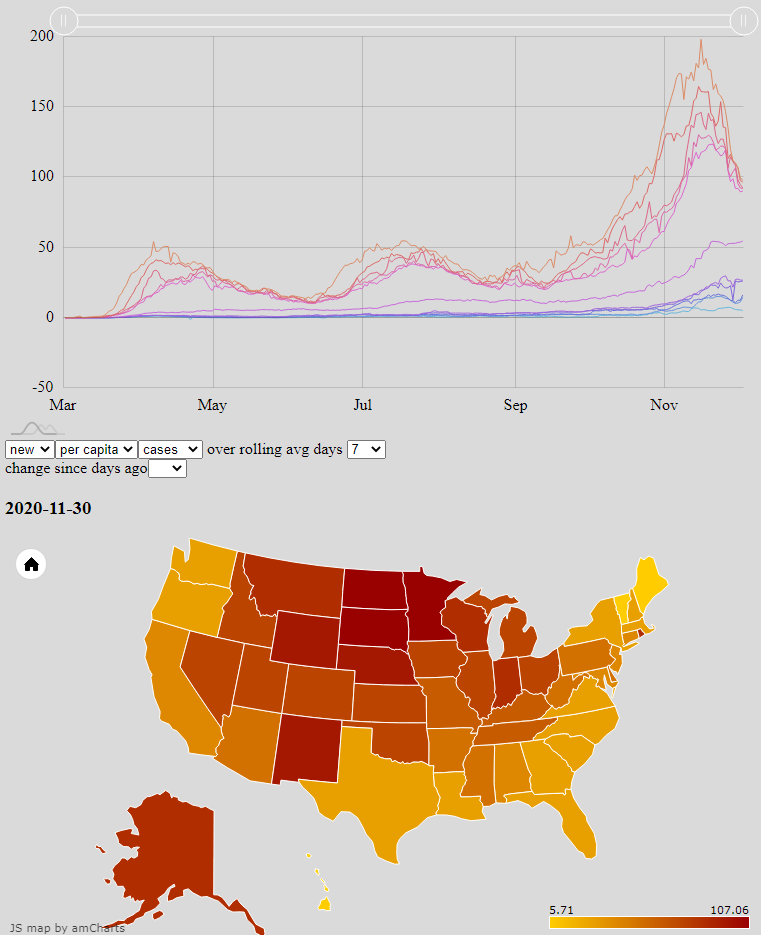
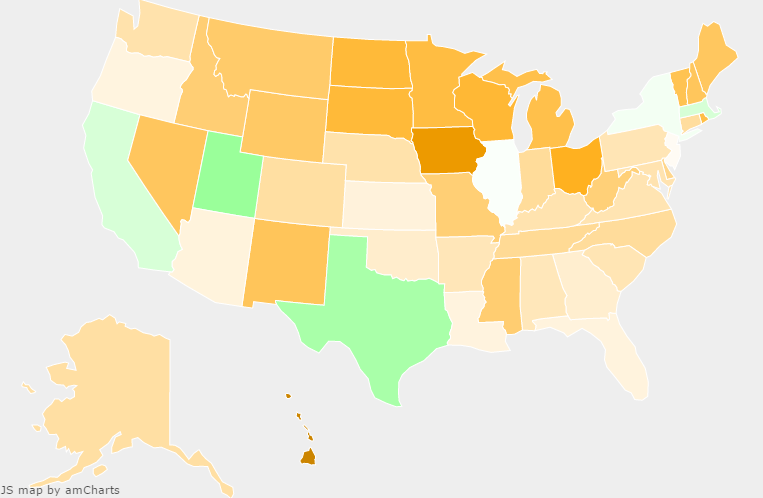
Many websites and news outlets provide coverage and analysis of Covid-19 trends. Graphs and maps are among the best way to convey them, but I can never find the combination of data most interesting to me. Google, for example, has great tools to show changes over time at the county, state, and national levels; but the comparison of regions against each other is limited and clunky. The Johns Hopkins Covid Dashboard meanwhile has heatmaps for easily seeing how regions compare against each other, but the data are only a single and recent snapshot. One of NPR’s most interesting graphs overlays the new cases in all 50 states, but does so with logistical scales that show daily new cases as a function of total cases rather than calendar date; and only one state may be compared against just New York at a time.
I set out to improve the situation for myself by rendering the raw CDC data, updated daily, with my own choice of axes and metrics. The publicly available result is an interactive combination of a line graph and heat map, both powered by amCharts, which mutually update each other’s state. The user may select which core data set to draw from, how to aggregate that data, and then either which date to focus on or which two states to compare. Most significantly, the line graph plots the median and the top- and bottom-five states — key percentiles — for a given data aggregation to show how outlier states change in both value and identity over time.